







ANNEXE 2 - ÉLÉMENTS SUR LA PRÉCISION DES SONDAGES : CONTRIBUTION DE M. PASCAL ARDILLY (SOCIÉTÉ FRANÇAISE DE STATISTIQUES)
_______
Les statisticiens d'enquête ont pour mission de mettre en oeuvre des méthodes permettant de connaître « au mieux » des grandeurs définies sur une population. Ces grandeurs sont le plus souvent des moyennes, des totaux ou des proportions. Par exemple, juste avant une élection, on souhaite connaître la proportion d'électeurs qui vont voter pour un candidat donné. Les valeurs exactes de ces grandeurs - que l'on appellera paramètres - peuvent être obtenues, en situation idéale, par recensement, c'est-à-dire par une collecte exhaustive des informations. Mais cette option est le plus souvent trop onéreuse et irréalisable : il est alors possible d'opter pour une solution alternative beaucoup moins lourde en organisant une enquête par sondage, c'est-à-dire une collecte de données auprès d'une partie seulement de la population.
Toute enquête par sondage se construit en distinguant deux étapes essentielles : la sélection de l'échantillon d'une part et le choix de la méthode d'estimation d'autre part, c'est-à-dire du processus de traitement des données collectées qui va fournir une valeur supposée proche du paramètre inconnu - valeur que l'on appelle estimation. L'économie de moyens a néanmoins une contrepartie qui est l'erreur d'échantillonnage : c'est le fait que l'estimation produite par le sondage va dépendre de l'échantillon tiré, avec pour corollaire l'existence d'un inévitable écart entre le paramètre et son estimation. En fin d'opération, il est souhaitable d'apprécier la qualité de l'estimation produite, en particulier de mesurer l'erreur d'échantillonnage.
L'erreur d'échantillonnage
L'erreur d'échantillonnage s'apprécie au travers
de deux composantes : le biais et la variance. Pour illustrer ces
concepts, on place sur un axe la proportion exacte
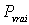 (inconnue) d'électeurs votant pour un candidat donné et
on imagine tous les échantillons possibles que l'on peut construire
à partir de la population complète (le nombre de ces
échantillons est gigantesque) : chaque échantillon donne lieu
à une estimation qui lui est propre et qui se positionne sur l'axe au
moyen d'une petite croix.
(inconnue) d'électeurs votant pour un candidat donné et
on imagine tous les échantillons possibles que l'on peut construire
à partir de la population complète (le nombre de ces
échantillons est gigantesque) : chaque échantillon donne lieu
à une estimation qui lui est propre et qui se positionne sur l'axe au
moyen d'une petite croix.
Un biais existe dès lors que la moyenne des
estimations, formée à partir de l'ensemble de tous les
échantillons que l'on peut constituer dans la population, diffère
du paramètre : graphiquement, c'est le cas lorsque la moyenne des
petites croix - soit
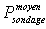 - n'est pas égale
à
- n'est pas égale
à
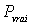 . Dans le cas contraire, on a un plan
de sondage sans biais.
. Dans le cas contraire, on a un plan
de sondage sans biais.
La variance traduit quant à elle une forme
d'instabilité des estimations : si l'estimation est
numériquement très sensible à l'échantillon
tiré, il y aura une grande variance. Graphiquement, il y a une grande
variance lorsque les croix sont très étalées le long de
l'axe, et une petite variance si elles sont concentrées à un
endroit quelconque de l'axe (qui n'est pas nécessairement égal
à
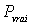 , ni même proche de ce
paramètre).
, ni même proche de ce
paramètre).
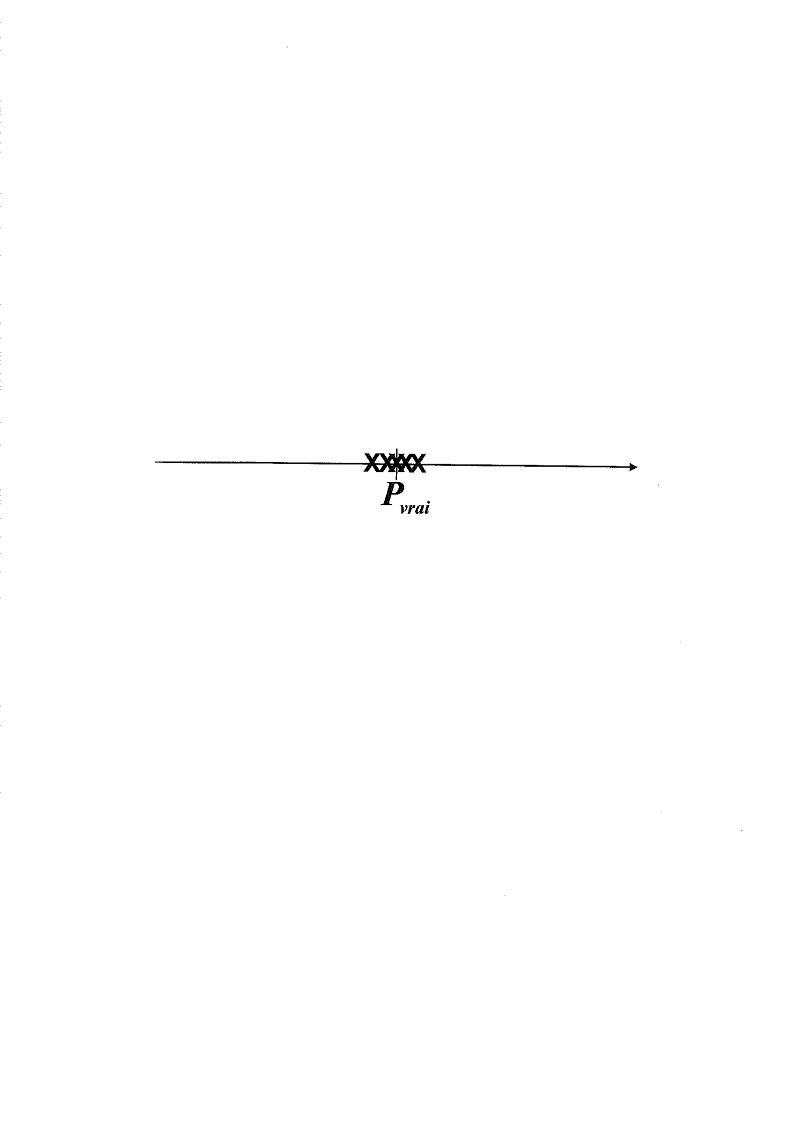
Situation 1 : pas de biais, faible variance

Situation 2 : biais, faible variance
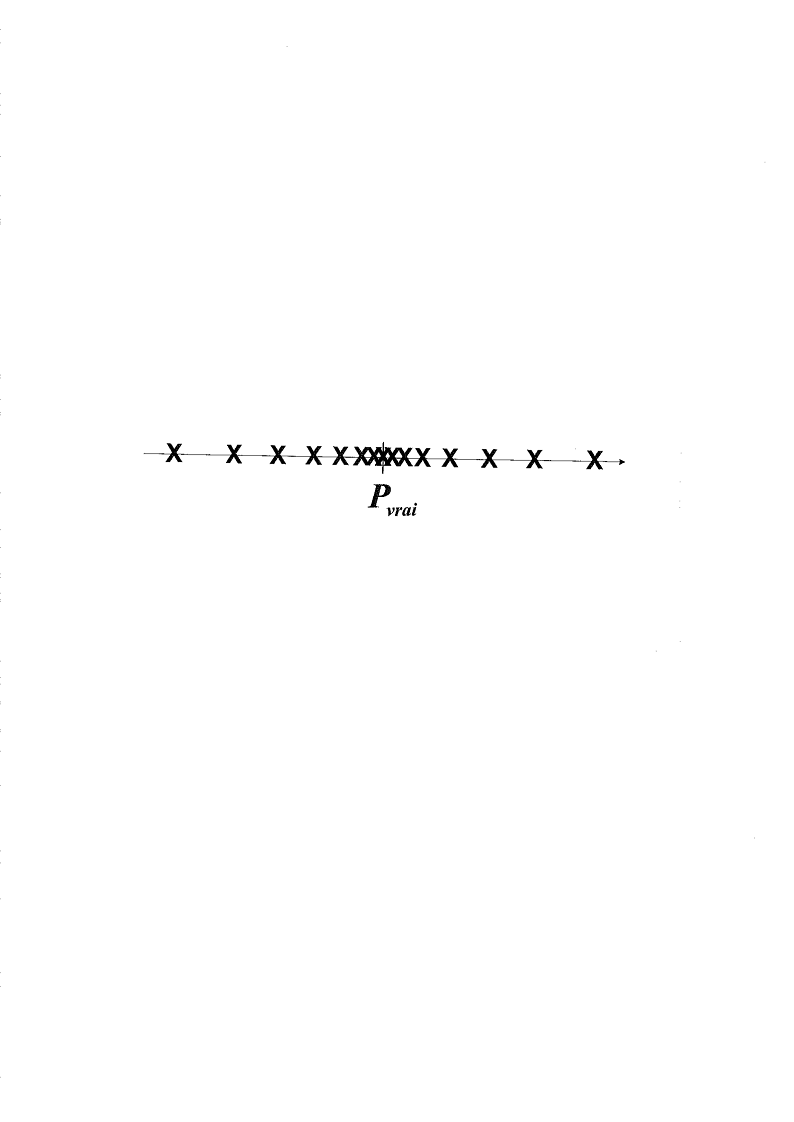
Situation 3 : pas de biais, grande variance
L'expression mathématique d'un biais ou d'une variance dépend à la fois de la méthode d'échantillonnage et de la procédure d'estimation. Dans tous les cas, dans l'approche de la théorie classique des sondages, il est nécessaire de connaître le contexte probabiliste qui préside au tirage des individus de l'échantillon. Autrement dit, il faut être capable de dire avec quelle probabilité un individu a été échantillonné (on parlera de ''probabilité de sélection''). Dans le cas contraire, on ne peut pas obtenir d'erreur d'échantillonnage par un calcul rigoureux.
La problématique des intervalles de confiance
La variance n'est pas le concept le plus opérationnel
en matière d'erreur d'échantillonnage : en effet, le plus
souvent, on diffuse des intervalles de confiance pour juger de la
qualité d'une estimation. L'intervalle de confiance est constitué
par une limite inférieure et une limite supérieure,
calculées de telle sorte qu'il y ait 95 chances sur 100 pour que le
paramètre recherché
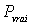 se situe
entre ces limites. La théorie de l'intervalle de confiance fait appel
à quelques hypothèses techniques dont les deux principales sont :
premièrement, la taille d'échantillon doit être "assez
grande" (ce qui est généralement satisfait) et
deuxièmement, l'estimation doit être sans biais. La seconde
condition nous intéresse tout particulièrement car nous verrons
que les estimations empiriques sont biaisées. Sans le justifier ici,
signalons que l'intervalle de confiance dit "à 95%" se construit en
général ainsi : la limite inférieure est égale
à l'estimation issue de l'enquête moins deux fois la racine
carrée de la variance, et la limite supérieure est égale
à l'estimation issue de l'enquête plus deux fois la racine
carrée de la variance.
se situe
entre ces limites. La théorie de l'intervalle de confiance fait appel
à quelques hypothèses techniques dont les deux principales sont :
premièrement, la taille d'échantillon doit être "assez
grande" (ce qui est généralement satisfait) et
deuxièmement, l'estimation doit être sans biais. La seconde
condition nous intéresse tout particulièrement car nous verrons
que les estimations empiriques sont biaisées. Sans le justifier ici,
signalons que l'intervalle de confiance dit "à 95%" se construit en
général ainsi : la limite inférieure est égale
à l'estimation issue de l'enquête moins deux fois la racine
carrée de la variance, et la limite supérieure est égale
à l'estimation issue de l'enquête plus deux fois la racine
carrée de la variance.
La perception du sens de l'intervalle de confiance est
souvent erronée : il ne faut surtout pas imaginer que le vrai
paramètre
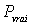 se trouve a priori "quelque
part" de manière uniforme au sein de cet intervalle. Derrière
cette notion, il y a des éléments probabilistes qui montrent que
se trouve a priori "quelque
part" de manière uniforme au sein de cet intervalle. Derrière
cette notion, il y a des éléments probabilistes qui montrent que
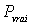 se trouve plus probablement plus près
du centre de l'intervalle que de ses extrémités : plus on se
rapproche du centre de l'intervalle, plus on a de chances d'y trouver
se trouve plus probablement plus près
du centre de l'intervalle que de ses extrémités : plus on se
rapproche du centre de l'intervalle, plus on a de chances d'y trouver
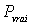 (techniquement, l'estimation suit une loi
probabiliste bien connue appelée loi de Gauss).
(techniquement, l'estimation suit une loi
probabiliste bien connue appelée loi de Gauss).
Par ailleurs, notons que le choix de la probabilité de 95 % est extrêmement courant en pratique, on pourrait même dire systématique, mais néanmoins largement conventionnel : en effet, on pourrait tout aussi bien opter pour des intervalles de confiance associés à une autre probabilité. C'est évidemment un moyen d'influer - de manière plus ou moins insidieuse il est vrai - sur l'amplitude de l'intervalle de confiance. Ainsi, l'intervalle de confiance à 90% sera plus étroit que l'intervalle à 95%, ce qui donnera certes une apparence de meilleure précision mais par définition on augmente le risque d'une mauvaise prévision du résultat des élections. De ce point de vue, les sondages électoraux ont la spécificité d'être confrontés ultérieurement à la vraie valeur (en l'absence de changements d'opinion...) et cet aspect est essentiel en termes de communication. A l'opposé, pour limiter les risques de mauvaise prévision, on peut construire un intervalle de confiance couvrant la vraie valeur avec plus de 95 chances sur 100 - mais l'intervalle va s'élargir : si on opte pour un intervalle de confiance à 99%, les limites de l'intervalle sont construites en calculant plus -ou moins - 2,6 fois la racine carrée de la variance (au lieu de 2) : la largeur de l'intervalle augmente donc de 30%.
Sondages probabilistes et sondages empiriques
Si on s'intéresse à la phase d'échantillonnage, on distingue traditionnellement deux classes de méthodes : d'une part les échantillonnages probabilistes, d'autre part les échantillonnages empiriques - la méthode empirique la plus connue étant la méthode des quotas.
Les sondages probabilistes ont pour caractéristique de permettre le calcul de la probabilité de sélection de chaque individu de la population couverte par l'enquête. L'échantillonnage probabiliste relève en effet de règles de sélection extrêmement précises dans une population au sein de laquelle chaque individu est clairement identifié. Une méthode de tirage totalement objective (un "algorithme" mathématique), sans aucune intervention humaine, permet d'associer à chaque individu de la population une probabilité connue d'être sélectionné. Pratiquement, c'est un programme informatique qui tire l'échantillon à partir d'un fichier informatique qui recense l'intégralité de la population (on parle de base de sondage).
A l'opposé, les sondages empiriques sont conçus de telle sorte qu'on ne puisse pas calculer rigoureusement les probabilités de sélection des individus enquêtés. L'échantillonnage empirique - disons de type quotas - relève d'une sélection non totalement contrôlée, offrant une composante subjective parce que la sélection est concrètement réalisée sur le terrain par l'enquêteur. Ce dernier dispose bien entendu de consignes pour limiter cette part d'appréciation subjective au moment de l'échantillonnage mais il conserve - inévitablement - une liberté qui ne permet pas de maitriser les aspects probabilistes de la sélection. L'échantillonnage empirique est donc pénalisant du point de vue de la théorie classique des sondages : de fait, il condamne de manière définitive toute mesure formelle de la qualité à partir des notions classiques de biais et de variance d'échantillonnage. Cet aspect est à l'origine des critiques et des difficultés attachées aux méthodes empiriques.
Méthodes de sondage et calculs d'erreur d'échantillonnage
Les plans de sondage probabilistes débouchent presque toujours sur la mise en oeuvre d'estimations sans biais (ou de biais négligeable). La théorie des sondages probabilistes est riche et s'est beaucoup développée récemment : elle permet de mener des calculs de variance, certes plus ou moins compliqués selon la méthode de sélection choisie et selon la méthode d'estimation retenue (le calcul de précision est plus difficile, bien naturellement, lorsque l'échantillonnage est lui-même compliqué). Certains phénomènes - comme la non-réponse - et certains traitements statistiques - comme les redressements - vont contribuer à cette complexité. Néanmoins, on maitrise très honorablement ces aspects avec les outils théoriques et logiciels dont on dispose. S'il y a une seule règle statistique à énoncer ici, c'est celle qui traduit la diminution de la variance avec la taille de l'échantillon : avec un tirage équiprobable d'individus (tirage "totalement au hasard"), l'intervalle de confiance a une largeur qui varie comme l'inverse de la racine carrée de la taille de l'échantillon : pour diviser par 2 la largeur de l'intervalle, il faut donc un échantillon 4 fois plus gros. Si l'échantillonnage probabiliste est d'une autre nature (par exemple si on tire les individus avec des probabilités de sélection inégales), la règle doit être adaptée.
Nous avons déjà signalé l'existence d'un biais théorique dans les sondages empiriques. Ce biais peut s'exprimer par une formule mathématique mais il n'est pas calculable numériquement (évidemment, sinon on corrigerait toutes les estimations en leur retranchant ce biais...). On peut montrer que le biais dépend très largement de la relation qui existe, au sein de chacune des sous-populations déterminées par les quotas, entre la variable qui permet de définir le paramètre (pour un sondage électoral, c'est une variable qui vaut 1 si l'individu déclare voter pour le candidat qui nous intéresse, et 0 sinon) et la probabilité de sélection de l'individu par l'enquêteur. Il a par ailleurs la très désagréable propriété de ne pas diminuer lorsque la taille de l'échantillon augmente.
L'existence de ce biais est assez intuitive et nous donnons ici un exemple un peu caricatural mais néanmoins éclairant : si on effectue une enquête sur l'emploi du temps par une méthode empirique (disons par quotas), il est fort probable que l'on aboutira à une surestimation du temps moyen d'inactivité des individus : en effet, l'enquêteur va plus facilement contacter des personnes qui sont à leur domicile, ne serait-ce que du fait des horaires habituels d'enquête. L'échantillon sera probablement déséquilibré avec une sous représentation des personnes qui travaillent beaucoup : il y a là, par nature, une corrélation positive pénalisante entre la probabilité de sélection et la variable "temps d'inactivité"...
La littérature relate un risque marqué de sous-représentation, dans n'importe quelle enquête par quotas, des personnes ayant un faible niveau d'instruction. En effet, les enquêteurs vont naturellement prendre des contacts avec des personnes proches de leur niveau social. De même, les étrangers seront probablement sous-représentés à cause de la difficulté de certains à s'exprimer et à comprendre les questions. Plus généralement, on peut craindre que l'enquêteur, tout en respectant ses quotas, évite (plus ou moins consciemment) certaines catégories de personnes, certains quartiers, certains types de logements, ce qui aura inévitablement une conséquence sur les proportions finalement diffusées... Seul l'échantillonnage aléatoire a cette faculté d'éliminer tout risque de liaison insidieuse - modulo le phénomène de non-réponse qui vient hélas, de toute façon et dans tous les cas, introduire une forme de corrélation de cette nature (mais que l'on essaie de corriger avec des méthodes scientifiques bien définies).
Bien entendu, pour tenter de traiter ce problème de biais intrinsèque, des éléments de solution existent (choix pertinent des quotas, formation des enquêteurs, consignes d'enquête strictes et bien adaptées, contrôles statistiques, contrôles de terrain, ...) mais par nature ils restent fragiles et très dépendants du réseau d'enquêteurs et du professionnalisme de l'organisme qui a la responsabilité de l'enquête. Certes, cette remarque vaut aussi pour les sondages probabilistes, mais à un niveau sensiblement moindre.
Quant à la variance, nous rappelons qu'elle ne se calcule pas non plus à partir d'un échantillonnage empirique. Très succinctement, sur le plan qualitatif, on résumera le contexte en disant que les contraintes imposées sur la structure de l'échantillon par les quotas constituent un élément qui limite à l'évidence l'ampleur de la variance - mais d'une façon que l'on ne peut pas formaliser. Cette question doit d'ailleurs être rapprochée des possibilités offertes par les plans de sondage probabilistes utilisant des informations externes et cela nous renvoie à d'autres développements.
En pratique, nous constatons que certains sondages empiriques - électoraux ou portant sur d'autres thèmes - donnent lieu à des intervalles de confiance. L'intention de mesurer et de diffuser l'erreur d'échantillonnage est très louable et doit être encouragée selon nous, mais il faut être clair sur le sens de ces calculs : d'une part ils négligent le biais (sans ce parti pris, il n'y a pas d'intervalle de confiance possible), d'autre part ils résultent bien d'une assimilation à un échantillonnage probabiliste.
L'approche alternative par modélisation des comportements individuels
Si la théorie classique des sondages sert peu les sondages empiriques (la littérature technique consacrée à l'échantillonnage empirique est, pour cause, très maigre), en revanche, il existe une théorie statistique des modèles qui fournit des justifications plus précises à la méthode des quotas. Dans cette théorie, en utilisant d'autres concepts que ceux de la théorie classique, il est possible d'établir des intervalles de confiance rigoureusement, sous certaines conditions.
L'approche par modèle relève d'une philosophie tout à fait particulière. Dans l'approche traditionnelle des sondeurs, l'aléa est limité à la composition de l'échantillon et les erreurs s'apprécient par rapport à cet aléa uniquement. En particulier, les opinions sont considérées comme des informations déterministes, c'est-à-dire qui n'ont pas une nature aléatoire. Dans l'approche par modèle, la méthode de sélection de l'échantillon a une importance bien moindre, et on s'appuie sur un modèle de comportement pour expliquer l'opinion d'un individu, à un moment donné, par un ensemble de variables connues sur l'ensemble de la population (dites "variables explicatives"). Par exemple, on va considérer que la probabilité de voter pour un candidat donné est une fonction du sexe, de l'âge, du diplôme, du type de logement dans lequel on réside, des différents votes exprimés aux dernières élections, de l'inscription à tel ou tel parti politique, etc.... La technique mathématique permet d'obtenir une estimation de vote moyen sur l'ensemble de la population, à partir des données collectées sur un échantillon d'individus et en utilisant les informations donnant la structure de la population complète selon les variables explicatives retenues.
Cette méthode existe, elle est techniquement réalisable, et modulo l'élément fondamental qui suit, elle permet effectivement de produire des estimations sans biais (ou presque) et d'en apprécier la variance (donc on peut fournir des intervalles de confiance). Il est même possible d'effectuer des optimisations qui produisent les "meilleures" estimations en un certain sens. Néanmoins, elle souffre d'un handicap considérable, qui a de bonnes raisons de la discréditer complètement auprès de certains utilisateurs : les résultats qu'elle produit sont totalement dépendants de la pertinence du modèle. En effet, un modèle est ni plus ni moins qu'une hypothèse de comportement a priori des individus de la population, et même si on dispose par ailleurs d'outils techniques permettant d'apprécier la force de cette hypothèse, on ne peut pas se prémunir scientifiquement contre cette critique: le résultat obtenu est largement sensible au modèle mis en oeuvre. C'est d'ailleurs ce qui fait toute la force des sondages traditionnels, pour lesquels les estimations ne dépendent d'aucune hypothèse - mais évidemment cela suppose la mise en oeuvre d'un plan de sondage respectant certains critères.
Que peut-on en penser ?
L'auteur de cette note est convaincu que la méthode des quotas est acceptable si et seulement si elle est mise en oeuvre par un organisme professionnel, expérimenté, offrant des garanties quant au processus de collecte et un minimum de transparence pour ce qui concerne sa pratique et ses calculs. Certes il est toujours mathématiquement préférable, à taille d'échantillon donnée, de pratiquer de manière aléatoire, mais en cas d'impossibilité (base de sondage inexistante, coût trop élevé, impératif de délais,...), il n'y a pas non plus lieu de stigmatiser outre mesure l'approche empirique dès lors qu'elle est sérieusement mise en oeuvre. Un organe de contrôle ayant des moyens techniques suffisants doit être en mesure d'en juger, et cela au cas par cas (la commission des sondages doit être à l'évidence cet organe, mais il y a certainement lieu de renforcer ses moyens techniques).
Le contrôle de la qualité du processus de collecte passe donc par une mise à disposition d'informations relatives au réseau d'enquêteurs, à leur formation, à leur contrôle et aux consignes de terrain. Il est aussi nécessaire de relativiser l'impact de l'échantillonnage : d'une part il ne faut pas oublier qu'il existe bien d'autres erreurs que l'erreur d'échantillonnage, probablement au moins aussi perturbatrices en matière de mesure des opinions politiques : non-réponse, erreurs de réponse (volontaires ou non) sur ce sujet sensible, volatilité de l'opinion dans le temps, d'autre part l'échantillonnage ne préjuge pas de tous les traitements qui sont effectués ultérieurement, en phase d'estimation, et qui ont évidemment des conséquences déterminantes sur les résultats diffusés : l'échantillonnage probabiliste ne protégerait l'utilisateur contre aucun de ces risques !
Puisque le biais ne peut être apprécié que qualitativement, sous les réserves énoncées ci-dessus, l'appréciation quantitative de l'erreur ne peut concerner que la variance d'échantillonnage. Il s'agit seulement d'une composante de l'erreur totale mais à partir du moment où la Commission compétente considère que l'échantillonnage empirique apparait assimilable à un échantillonnage probabiliste, il n'y a plus d'obstacle à estimer cette variance. La technique le permet, en tout cas. Il y a donc une logique à exiger cette estimation, sous condition probablement d'un consensus sur la technique de calcul (afin de cadrer à minima les expressions utilisées par les instituts).
En ce qui concerne l'utilisation éventuelle de modèles de comportement, l'auteur de cette note aurait une réticence - qui n'engage que lui - à fonder les estimations "grand public" sur des modèles de comportement, un peu par principe, mais surtout beaucoup plus par le fait que les utilisateurs, dans leur grande majorité, ne sont pas techniciens et ne pourront pas raisonnablement apprécier la nature des risques pris avec une approche par modèle. Cela étant, il est toujours possible aux instituts d'effectuer en parallèle des estimations selon cette approche, à titre expérimental et par souci de confrontation avec l'approche traditionnelle, au moins pour l'information de la Commission des sondages.
Dans tous les cas, il est probablement nécessaire de réfléchir au contenu des encadrés méthodologiques accompagnant la diffusion des résultats, dont l'obligation serait bienvenue : il doit en effet être possible de trouver des formulations non agressives et non dévalorisantes pour les responsables du sondage qui permettent de signaler qu'il s'agit d'une approche comportant un certain degré d'empirisme - et peut-être rappelant l'existence d'erreurs autres que la variance d'échantillonnage (la diffusion de cette seule composante pouvant faire illusion et tromper les utilisateurs sur la nature de l'erreur totale).