







C. LA CONCEPTION ET LE FONCTIONNEMENT D'UN MODÈLE D'INTELLIGENCE ARTIFICIELLE GÉNÉRATIVE
1. Une diversité de modèles et d'acteurs
Un modèle d'IA générative est un modèle d'IA qui a la capacité de générer un contenu nouveau et original (un texte, une image, une vidéo...), en se basant sur ce qu'il a appris. Un modèle d'IA générative n'est pas forcément un modèle de fondation (voir supra).
Il existe plusieurs types de modèles d'IA générative :
· un modèle de langage est un modèle d'IA générative capable de générer un contenu textuel. On parle de grand modèle de langage (Large Language Model ou LLM) lorsque le modèle possède un grand nombre de paramètres. Les LLM sont les modèles d'IA générative les plus courants aujourd'hui ; ChatGPT est le plus connu d'entre eux ;
· un modèle de diffusion est un modèle d'IA générative capable de générer un contenu visuel. C'est le cas, par exemple, de DALL-E et de Midjourney ;
· un modèle multi-modal est un modèle d'IA générative capable de générer un contenu sous différents formats (texte, image, son, vidéo...) ; GPT-4 en est.
Différents acteurs interviennent dans la chaîne de développement et d'utilisation d'un modèle d'IA, parmi lesquels :
· le « fournisseur » : selon la définition qu'en donne le règlement européen établissant des règles harmonisées concernant l'intelligence artificielle (RIA) du 13 juin 2024, il s'agit d' « une personne physique ou morale, une autorité publique, une agence ou un autre organisme qui développe ou fait développer un système d'IA ou un modèle d'IA à usage général et le met sur le marché ou met le système d'IA en service sous son propre nom ou sa propre marque, que ce soit à titre onéreux ou gratuit ».
Exemples de fournisseurs d'IA : OpenAI, Google, Amazon, Microsoft, IBM, Mistral AI...
· le « développeur » : il s'agit du professionnel capable de concevoir un modèle d'IA. Ses missions incluent l'analyse des besoins, la collecte et la préparation des données, le choix de la technique d'apprentissage, l'entraînement du modèle, son évaluation, son intégration dans une application ou un système, sa surveillance...
· le « déployeur » : selon la définition du RIA, il s'agit de « toute personne physique ou morale, autorité publique, agence ou autre organisme qui utilise un système d'IA sous sa responsabilité, sauf si l'utilisation est à des fins personnelles non professionnelles ».
exemples de déployeurs d'IA : une banque qui a recours à une IA pour analyser les dossiers de prêt, un cabinet RH qui déploie une IA pour trier automatiquement des CV, une entreprise de cybersécurité qui utilise l'IA pour détecter des fraudes, un organisme public qui met en place un chatbot (assistant virtuel de conversation) automatisé pour répondre aux citoyens...
2. Les différentes étapes de la conception d'un modèle d'intelligence artificielle générative
La chaîne de conception d'un modèle d'IA générative comprend plusieurs étapes :

a) La collecte des données d'entraînement ou le grand moissonnage
Les données d'entrée (aussi dénommées données brutes) sont un élément-clef pour la création d'un modèle d'IA : ce sont en quelque sorte les ingrédients sans lesquels « la recette » IA ne peut être cuisinée. Sans données, une IA reste inerte, incapable d'apprendre et encore moins de prendre des décisions pertinentes.
Le terme « données » revêt ici un sens générique : il peut s'agir de données textuelles, de données d'image, de données sonores, de données vidéo, ou de données multi-supports...
Pour garantir l'efficacité, la précision et la fiabilité du modèle d'IA, les données doivent répondre à plusieurs critères :
- elles doivent être en quantité suffisante : pour qu'un modèle soit bien entraîné, il a besoin d'analyser beaucoup d'exemples, donc un volume très important de données ;
- elles doivent être de qualité : sans données pertinentes, précises et fiables, même les modèles d'IA les plus sophistiqués peuvent générer des résultats biaisés ou erronés ;
- elles doivent être diverses : plus les données sont variées, plus le modèle améliore la précision et la pertinence de ses réponses.
Il existe différents canaux de collecte de données d'entraînement.
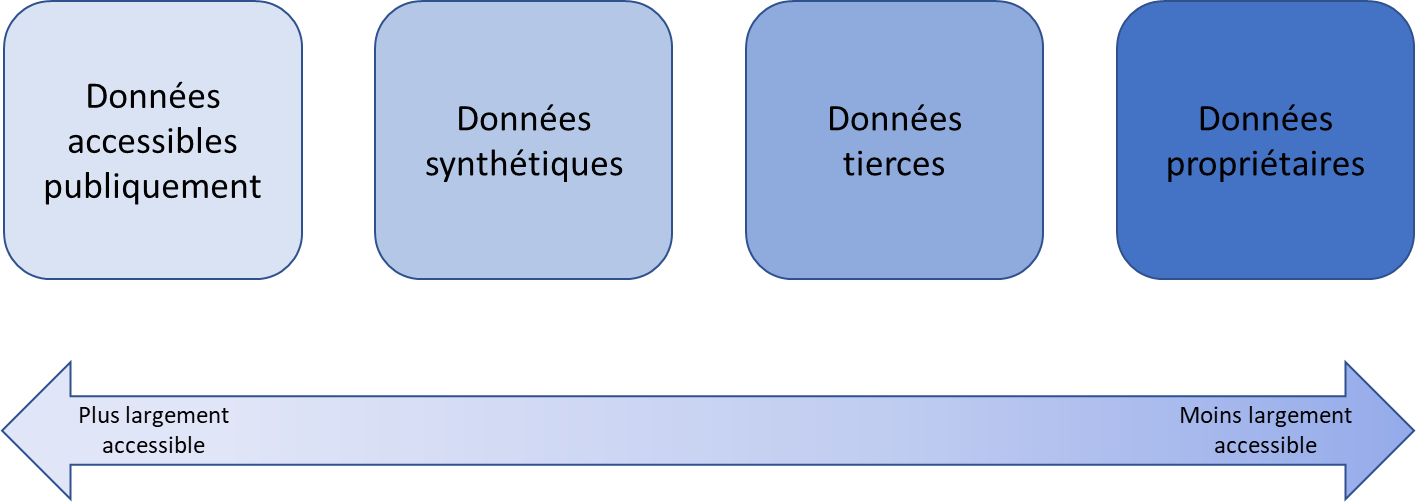
La plus grande source d'approvisionnement est constituée de données accessibles publiquement en ligne. Le fait que ces données soient « publiques » ne signifie pas qu'elles soient librement exploitables - certaines peuvent être protégées par des droits, comme le droit de la propriété intellectuelle s'il s'agit d'un contenu considéré comme « original » (texte, image, vidéo...) ou le droit au respect de la vie privée s'il s'agit de données à caractère personnel (nom, image ou vidéo identifiant une personne physique), ni qu'elles soient licites - certaines peuvent avoir été piratées.
L'accès à ces données publiques se fait via des moteurs de recherche généralistes comme Google ou Yahoo, des bases de données spécialement constituées pour servir à alimenter les modèles d'IA comme Laion, des bases de données spécialisées dans certains domaines comme Library Genesis (LibGen) pour les contenus scientifiques, ou la base de données de l'organisation Common Crawl qui constitue une sorte de répertoire recensant tous les contenus trouvés sur Internet depuis une dizaine d'années4(*).
Pour collecter massivement et automatiquement des données librement accessibles en ligne, il est fait recours à la technique du web scraping qui signifie littéralement « raclage », mais qui est plus couramment traduite par le terme « moissonnage ». Elle permet, à l'aide de bots (applications logicielles automatisées) fonctionnant comme des robots « racleurs » ou « moissonneurs », de récupérer des données à partir du code source des pages Web concernées, puis de les restituer dans une base de données organisées de type tableur. De manière imaginée, cette opération revient à envoyer un robot dans une librairie pour qu'il rapporte des livres spécifiques. Dans le cas d'espèce, la librairie est un site Web et les livres sont des données.
Bien que les pratiques de moissonnage offrent des avantages importants en termes de rapidité, de quantité et de diversité des données collectées, elles posent de nombreuses questions sur la protection de la vie privée, le respect de la propriété intellectuelle, la rétribution des ayants droit. La Cnil a d'ailleurs régulièrement appelé à la vigilance concernant ces pratiques, dont la généralisation opère selon elle « un changement de nature quant à l'utilisation d'Internet, dans la mesure où toutes les données publiées en ligne par une personne sont désormais susceptibles d'être lues, collectées et réutilisées par des tiers, ce qui constitue un risque important et inédit pour les personnes ». En conséquence, la Cnil recommande la mise en place d'un encadrement législatif ad hoc5(*), qui permettrait à la fois de sécuriser les organismes y ayant recours, de réguler cette pratique et de protéger les données librement accessibles en ligne.
Il existe trois autres sources d'approvisionnement en données d'entraînement, qui sont d'un accès moins facile que la première :
· les données synthétiques, c'est-à-dire des données artificiellement conçues pour imiter les données du monde réel. Elles sont générées par des méthodes statistiques ou par des techniques d'IA ;
· les données propriétaires de tiers, à savoir des données collectées par des entités externes comme des courtiers en données. Les principales entreprises de ce secteur sont Experian, Equifax, Acxiom et Epsilon ;
· les données internes qui sont directement détenues par les entreprises développant des modèles d'IA.
Dans son récent rapport sur la rémunération des contenus culturels utilisés par les systèmes d'IA6(*) commandé par le Conseil supérieur de la propriété littéraire et artistique (CSPLA), la professeure Joëlle Farchy résume le degré d'accessibilité des différentes sources de données d'entraînement par le schéma suivant :
b) La préparation des données collectées
Avant d'être utilisées, les données brutes collectées doivent être préparées. Elles peuvent en effet comporter des anomalies, des incohérences, des doublons ou des valeurs manquantes. Une préparation rigoureuse permet de corriger ces problèmes qui pourraient entraîner des imprécisions, des biais, des erreurs, voire des hallucinations.
Cette étape comprend plusieurs tâches successives :
· le nettoyage des données : il vise à éliminer les anomalies, à corriger les erreurs, à supprimer les doublons, à remplacer les valeurs manquantes ;
· la structuration et la transformation des données : une fois nettoyées, les données doivent être préparées pour s'adapter aux exigences des algorithmes d'apprentissage. C'est là qu'intervient le processus dit de « tokenisation », par lequel les données sont segmentées en unités plus petites appelées tokens, plus faciles à appréhender par le modèle. S'en suit un processus d'encodage ou de vectorisation, au cours duquel chaque token est converti en valeur numérique que le modèle pourra directement traiter ;
· la normalisation et la mise à l'échelle des données : les données peuvent présenter des écarts importants en termes de grandeur ou d'échelle, ce qui peut perturber certains algorithmes d'apprentissage. La normalisation et la mise à l'échelle permettent de les harmoniser en ajustant leur valeur à une plage standard ;
· l'étiquetage des données : cette étape consiste à associer une annotation spécifique à chaque donnée. Cet étiquetage sert de guide pour l'apprentissage des modèles et garantit que les données sont interprétées correctement pendant l'entraînement ;
· l'enrichissement des données : pour améliorer la pertinence et l'affinage des données brutes, des informations supplémentaires peuvent être ajoutées. Cet enrichissement inclut l'intégration de métadonnées (c'est-à-dire de données fournissant des informations sur d'autres données), l'ajout de contextes ou la combinaison avec des données externes complémentaires ;
· l'équilibrage des données : un jeu de données déséquilibré, où certaines catégories sont sur-représentées, peut introduire des biais dans les modèles d'IA. L'équilibrage consiste à ajuster la distribution des données en réduisant ou en augmentant certaines catégories de données par rapport à d'autres ;
· la validation des données : cette étape inclut des contrôles automatiques ou manuels pour détecter d'éventuelles anomalies restantes et vérifier que le jeu de données est conforme aux exigences du projet ;
· le partitionnement des données : la dernière étape de la préparation des données consiste à les diviser en trois ensembles distincts :
ü un premier ensemble, comprenant généralement entre 70 % et 80 % des données, est consacré à l'entraînement du modèle ;
ü un deuxième ensemble, composé entre 10 % à 15 % des données, à sa validation ;
ü un troisième ensemble, également composé de 10 % à 15 % des données, à son test.
c) L'entraînement du modèle à partir des données préparées
Si la collecte et la préparation des données s'apparentent en quelque sorte à la base de la construction « IA », le choix de la technique d'entraînement (machine learning, deep learning) et des algorithmes associés constituent son architecture générale.
Une fois cette architecture mise en place, l'étape de l'entraînement peut commencer. Elle consiste à alimenter le modèle en données préparées, à examiner les résultats sortants (outputs), à procéder à des ajustements pour améliorer le modèle, et à reproduire ces mêmes étapes autant de fois que nécessaire.
L'entraînement d'un modèle d'IA est donc un processus itératif, semblable à la manière dont un enfant acquiert une compétence par la répétition.
S'il s'agit d'un modèle de fondation, une étape supplémentaire peut être introduite, consistant à procéder à un ajustement (fine-tuning) pour le spécialiser. Le modèle est alors réentraîné sur des données d'affinage, spécialisées.
d) La validation et le test du modèle
Une fois que le modèle a réussi la phase d'entraînement initiale, la phase de validation consiste à utiliser à un jeu de données distinct du jeu de données d'entraînement. L'objectif est d'évaluer les performances du modèle à partir de nouvelles données, généralement plus complexes.
Après la validation du modèle, un nouveau jeu de données est utilisé pour tester l'exactitude du modèle. Si le modèle fournit des résultats précis avec ces données de test, il est prêt à être mis en service. Si le modèle présente des lacunes, le processus d'entraînement se répète jusqu'à ce que le modèle respecte les objectifs de performance définis.
e) La mise en production et le déploiement du modèle
La mise en production, aussi appelée phase d'inférence, correspond au processus par lequel un modèle, préalablement entraîné, est utilisé pour effectuer des prévisions ou produire un résultat à partir de nouvelles données - aussi appelées données « fraîches » ou « données d'ancrage » - sans nécessiter d'entraînement. L'apport de ces nouvelles données permet d'ancrer le modèle dans l'actualité ou dans un contexte bien spécifique.
Une fois le modèle ancré, il est prêt à être intégré dans une infrastructure d'hébergement déjà existante ou nouvellement créée, de type solution cloud, installation sur site Web, application spécifique... Le modèle peut être libre d'accès (open source) ou distribué sous licence.
Les trois grandes catégories de
données utilisées
pour le fonctionnement des modèles
d'IA
Les données d'entraînement, « raclées » en très grande quantité (de l'ordre de plusieurs millions voire plusieurs milliards) pour servir à entraîner le modèle.
Les données d'affinage ou d'ajustement, sélectionnées pour spécialiser le modèle sur certaines tâches.
Les données d'ancrage, « fraîchement » recueillies pour ancrer le modèle dans l'actualité.
* 4 Common Crawl est une organisation à but non lucratif américaine, créée en 2017, qui explore le Web et fournit gratuitement ses archives et ses ensembles de données au public. Par des opérations d'extraction mensuelles qui capturent des milliards de pages Web, la base de données de Common Crawl est devenue une source indispensable pour l'entraînement des modèles d'IA.
* 5 Avis de la Cnil du 15 décembre 2022 sur le projet « Polygraphe ».
* 6 « Rémunération des contenus culturels utilisés par les systèmes d'intelligence artificielle », projet de rapport - volet économique, mission confiée par le Conseil supérieur de la propriété littéraire et artistique, Joëlle Farchy et Bastien Blain, mai 2025.