







B. UNE SITUATION PRÉJUDICIABLE À TOUS
L'absence de rémunération et de transparence sur les données présente en réalité plusieurs risques très significatifs, non seulement pour les créateurs, mais également pour les fournisseurs d'IA, singulièrement en Europe.
1. Des menaces pour les créateurs
a) Un modèle économique fragilisé
Comme cela a été mentionné précédemment, les créateurs et toute la chaîne de valeur qui gravite autour d'eux (producteurs, éditeurs etc...) sont les premières victimes de l'usage sans rémunération des oeuvres. Ils subissent ainsi un double effet : en amont, leurs productions sont utilisées sans rémunération, en aval, l'utilisation qui est faite de leurs oeuvres nourrit un système qui à terme proposera des oeuvres en concurrence directe avec leurs propres productions.
Plus grave, l'absence de rémunération constitue un signal extrêmement négatif adressé par les fournisseurs au monde de la création, accréditant l'idée que les oeuvres n'auraient en elles-mêmes aucune valeur, au regard des éléments rappelés précédemment. Ce raisonnement ne tient cependant pas la route compte tenu de la dépendance des modèles d'IA à ces mêmes données, sans lesquelles ils ne peuvent produire aucun résultat.
La rémunération constitue donc a minima une reconnaissance de la valeur des données utilisées.
b) Donner aux créateurs les moyens de s'adapter à l'IA
Les relations entre IA et création ne se limitent pas à une forme de prédation et de concurrence déloyale. Les nombreux outils proposés par l'IA sont également des leviers qui offrent de nouvelles palettes d'expression artistique, comme cela a été expliqué dans la partie II du présent rapport.
Or l'intégration de nouvelles technologies suppose des actions d'acquisition de matériels et de formation aux nouveaux usages. Les effets spéciaux dans le cinéma ont pu se développer parce que les studios ont tout d'abord généré des revenus avec des productions classiques, revenus qui ont permis un bond technologique pour les oeuvres suivantes. Tel n'est pas le cas aujourd'hui, où les revenus demeurent pour l'instant concentrés entre les mains des seuls fournisseurs d'IA.
Il est donc essentiel que les revenus générés par l'IA soient aussi utilisés pour permettre aux créateurs de s'adapter à cette nouvelle révolution technologique dont ils doivent aussi être acteurs.
2. Une double incertitude pour les entreprises technologiques
Si les avantages de la gratuité des données semblent évidents pour les fournisseurs, il présente cependant à terme des risques significatifs pour leur développement, singulièrement pour les entreprises européennes.
a) Les risques communs à tous les fournisseurs d'IA
(1) Des incertitudes juridiques lourdes
Les entreprises de technologie soutiennent que l'utilisation des données est couverte, en Europe, par l'exception TDM - sans pour autant en respecter les termes, voir supra - et aux États-Unis, par le « fair use ».
Dans sa lettre précitée du 13 mars 2025, OpenAI en fait un point central : « Les États-Unis ont tellement de starts up dans le domaine de l'IA, attirent tellement d'investissements, et ont réalisé tellement d'avancées largement parce que la doctrine du fair use promeut le développement de l'IA. Dans d'autres marchés, les règles rigides de la propriété intellectuelle freinent l'innovation et l'investissement38(*) ».
Cependant, il n'existe pas encore de consécration devant les tribunaux américains de cette interprétation. Bien au contraire, plus de 60 contentieux sont actuellement engagés dans plusieurs secteurs pour contester l'application de la doctrine du fair use pour l'entraînement des IA. Ce débat ne concerne pas uniquement le secteur créatif. La plateforme Reddit a ainsi porté plainte contre la société Anthropic, créateur de l'IA « Claude », pour avoir utilisé sans autorisation les propos tenus publiquement sur son site. Reddit avait d'ailleurs conclu des accords avec plusieurs fournisseurs d'IA pour l'usage de ses contenus, dans des conditions permettant de protéger la vie privée de ses utilisateurs.
La situation est sensiblement la même en Europe. Pour la France, le Syndicat national de l'édition (SNE), la Société des gens de lettres (SGDL) et le Syndicat national des auteurs et des compositeurs (SNAC) ont ainsi saisi le tribunal judiciaire de Paris contre la société Meta, propriétaire de l'IA Llama, accusée d'utiliser leurs oeuvres sans leur consentement. D'autres actions sont également en cours.
Les fournisseurs d'IA sont donc engagés dans des contentieux juridiques des deux côtés de l'Atlantique, qui mettront probablement plusieurs années à être résolus par un recours aux juridictions supérieures. Or l'impact pour elles n'est pas négligeable. En effet, il n'existe pas de possibilité technique de « désentraîner » une IA. Si un jugement devait contraindre une entreprise à « retirer » un contenu, elle devrait de facto bâtir en totalité un nouveau modèle, pour un coût extrêmement élevé. Le risque juridique est d'autant plus important que le droit américain assortit les jugements de dommages et intérêts qui peuvent être très élevés.
Face à une incertitude juridique potentiellement mortelle, les fournisseurs d'IA auraient donc un intérêt majeur à régler en amont leurs relations avec les ayants droit, ce qui permettrait de « solder le passé » et d'ouvrir des perspectives de coopération mutuellement profitables.
(2) Vers l'effondrement des modèles ?
Les modèles d'IA ont utilisé d'énormes quantités de données pour parvenir à leur niveau actuel. De plus en plus de contenus présents en ligne sont désormais générés par des IA. Ainsi, environ 20 % des morceaux proposés par les services de streaming seraient totalement « synthétiques ».
En première analyse, une forme de « cercle vertueux » pour l'IA pourrait donc être engagée : des contenus synthétiques viendraient alimenter les bases d'entraînement pour perfectionner les IA. Cette thèse est cependant battue en brèche. Comme rappelé précédemment, plusieurs études récentes39(*) ont ainsi montré que les modèles d'IA ont tendance à subir une forme de dégénérescence quand la quantité de données synthétiques utilisée pour l'entraînement dépasse un certain seuil. Les nouveaux contenus générés sont d'une qualité de plus en plus faible, avec des erreurs qui se reproduisent et s'accentuent au fil des itérations. In fine, le modèle est menacé d'effondrement : il ne produit plus que des résultats sans pertinence.
Dans son rapport précité, Joëlle Farchy propose une illustration particulièrement parlante de l'appauvrissement et finalement, de l'effondrement d'une IA entraînée sur des contenus synthétiques.
Illustration de l'effondrement d'une IA
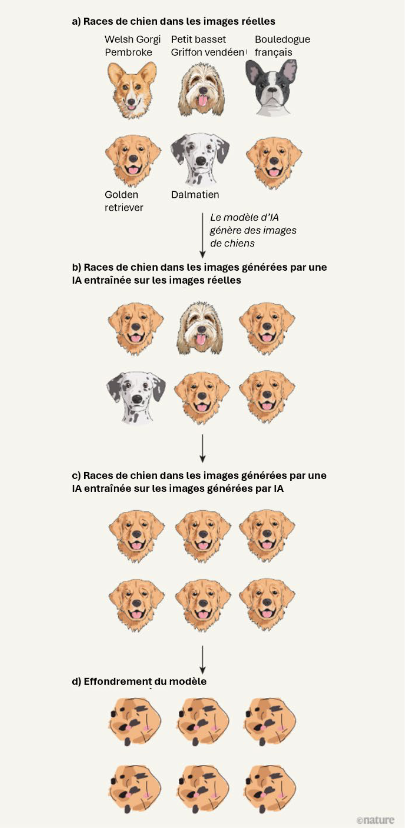
Les modèles d'IA ont donc besoin d'être sans cesse alimentés de contenus humains « originaux ». Au-delà des considérations mathématiques et statistiques qui conduisent à prédire l'effondrement, les requêtes en lien avec l'actualité sont particulièrement sensibles. Une IA doit pouvoir disposer de sources fiables pour répondre à une interrogation sur le résultat d'une élection, un résultat sportif ou un n'importe quel événement récent, et ne peut pas se fier aveuglément aux publications des réseaux sociaux.
Il est donc dans l'intérêt des fournisseurs d'IA de maintenir des secteurs de la création et de l'information puissants et de qualité pour ne pas appauvrir et détruire ses propres modèles. Or la prolifération actuelle de contenus synthétiques sur Internet, pour la plupart sans indication de leur origine, pose la question de la viabilité à terme des IA si les bases constituées pour leur entraînement ne sont pas précisément sourcées.
3. L'Europe, « idiot utile » des Américains ?
L'Europe affiche de grandes ambitions en matière de développement des IA et déploie une politique active de promotion de ces technologies dans l'espoir de faire de l'Europe « le continent de l'IA ». Elle semble cependant emprunter le chemin d'un alignement sur les pratiques américaines, jugées plus efficaces, dans l'espoir que des entreprises européennes puissent en tirer profit.
Le précédent de la LCEN
La volonté d'aligner le droit européen sur le droit américain s'est déjà manifestée avec les législations adoptées pour faire face à l'essor des technologies numériques au début des années 2000.
La directive 2000/31/CE du 8 juin 2000 a ainsi cherché à favoriser le développement des grandes entreprises européennes dans le secteur numérique, en reprenant pour l'essentiel le Digital Millennium Copyright Act adopté aux États-Unis en 1998. Transposé en droit français par la loi du 21 juin 2004 pour la confiance dans l'économie du numérique (LCEN), la directive a en particulier introduit le statut d'hébergeur, qui figure à l'article 6-I-2 de la LCEN. Ce statut exonère les plateformes de toute responsabilité pour les contenus qui y sont publiés par les usagers, sauf cas de signalement. À l'usage, il s'est révélé extrêmement favorable pour les entreprises américaines, sans permettre à l'Europe de développer ses propres technologies40(*).
Notre continent ne dispose cependant pour l'instant pas d'avantages en matière de prix de l'énergie, de marché des capitaux et de compétences technologiques dans le secteur des puces. De fait, le marché est actuellement très largement dominé par les États-Unis, comme le souligne l'étude de la Direction générale du Trésor de décembre 202441(*).
Part des différentes organisations dans le
nombre total de modèles
de fondation entre
le 1er janvier et
le 4 octobre 2024
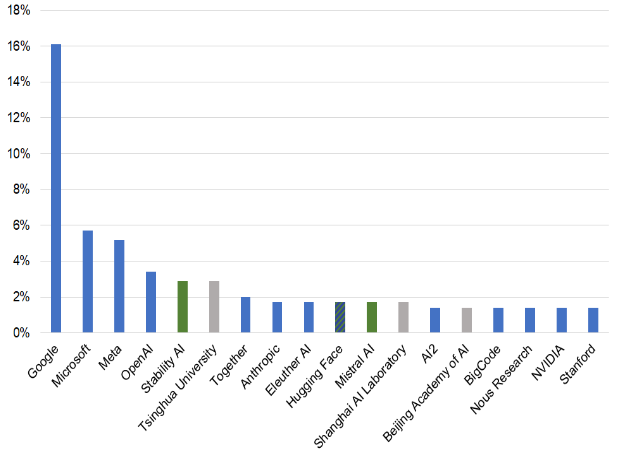
Source : Étude de la direction générale du Trésor
À l'opposé, l'Europe dispose de données-oeuvres de très grande qualité, exprimées en différentes langues et qui reflètent une large variété de sensibilités culturelles et artistiques. Cela constitue, avec la formation des ingénieurs, notre plus grand avantage comparatif sur la Chine et les États-Unis.
Dès lors, un alignement « par le bas » sur la protection des droits d'auteur pourrait ne pas être un encouragement au développement des entreprises européennes, mais plutôt une manière pour des sociétés déjà en position dominante de conforter leur position pour un coût quasi nul. L'administration américaine s'attaque d'ailleurs aux régulations européennes dans le domaine du numérique, qui vont de la protection des données personnelles - avec le RGPD adopté en mai 2018, depuis devenu un standard mondial - jusqu'aux Règlements européens de 2022 sur les services et les marchés numériques (DSA et DMA).
Protéger les données européennes en faisant respecter le droit d'auteur et la rémunération afférente est donc de nature à faire émerger un modèle européen respectueux de la création, éthique, et alimenté par des données de qualité dont l'usage ne souffrirait d'aucune incertitude juridique. Cette pratique permettrait à l'Europe, dans la concurrence qui va s'engager autour de l'IA, de ne pas être « l'idiot utile » des Américains et d'éviter de se trouver prisonnière d'un féodalisme numérique qu'elle subit déjà.
V. LES RECOMMANDATIONS DE LA MISSION D'INFORMATION POUR UN PARTAGE DE LA VALEUR ÉQUILIBRÉE ENTRE ACTEURS DE L'IA ET AYANTS DROIT CULTURELS, SOCLE SUR LEQUEL BÂTIR UNE TROISIÈME VOIE DE L'IA
Innovation de rupture, surtout depuis qu'elle est en capacité de générer des contenus ressemblant aux créations humaines, l'IA soulève des défis juridiques, économiques, culturels et éthiques à nos démocraties, même si on ignore encore largement ses limites.
À l'occasion de ses travaux, la mission d'information a pu prendre la mesure aussi bien des inquiétudes légitimes des ayants droit culturels face à une IA sans garde-fous, que des potentialités offertes par cette nouvelle donne technologique pour le secteur de la création artistique.
Elle est aussi pleinement consciente de l'enjeu stratégique de souveraineté que pose l'IA pour l'Union européenne, dans un contexte géopolitique marqué par l'émergence de « prédateurs », pour reprendre l'expression de Giulanio da Empoli42(*), et par les attaques en règle de la nouvelle administration américaine contre toute forme de régulation des géants de la tech.
Convaincue de la nécessité de maîtriser les risques liés à l'IA, tout en favorisant son potentiel d'innovation, la mission d'information souhaite poser les bases d'une régulation qui, au niveau européen, concilierait les intérêts de cette technologie et les préoccupations du secteur de la création.
Pour ce faire, la mission d'information formule huit grands principes qui devraient, selon elle, guider les parties prenantes sur la voie d'une rémunération appropriée pour l'utilisation des contenus culturels par les acteurs de l'IA, permettant de dépasser l'opposition stérile entre innovation et régulation et d'enclencher un cercle vertueux entre IA et création.
En termes de méthode, la mission recommande une réponse graduée en trois étapes, qui laisserait d'abord sa place à la concertation entre les parties prenantes, puis qui définirait, en cas d'échec de celle-ci, les moyens juridiques nécessaires au respect des intérêts légitimes des ayants droit culturels.
* 38 America has so many AI startups, attracts so much investment, and has made so many research breakthroughs largely because the fair use doctrine promotes AI development. In other markets, rigid copyright rules are repressing innovation and investment.
* 39 Par exemple : Ilia Shumailov et alii, Nature, juillet 2024 : AI models collapse when trained on recursively generated data - https://www.nature.com/articles/s41586-024-07566-y
* 40 Catherine Morin-Desailly a déposé le 27 septembre 2018 une proposition de résolution adoptée par le Sénat pour remettre en cause ces statuts d'hébergeur : https://www.senat.fr/dossier-legislatif/ppr17-739.html
* 41 La chaine de valeur de l'intelligence artificielle : enjeux économiques et place de la France https://www.tresor.economie.gouv.fr/Articles/54e356a7-2319-43d3-bb84-361430cc82e6/files/a66dc035-21da-4f10-9997-9516ffa7cc3f
* 42 « L'heure des prédateurs » Giuliano da Empoli, 2025